

1. Observability Nedir? (Log, Metric, Trace)
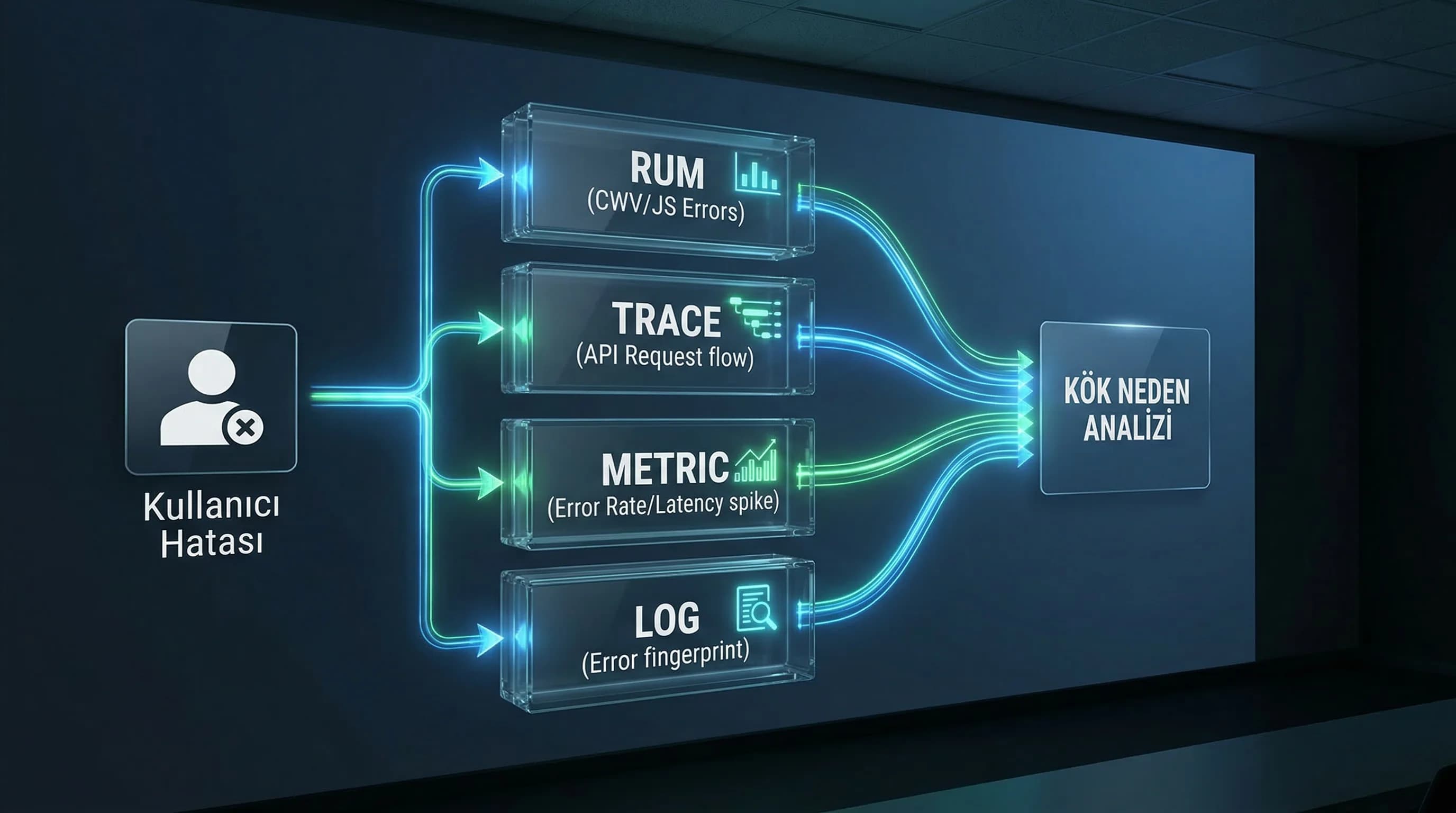
Observability, monitoring’in “ileri versiyonu” gibi düşünülür ama farkı şudur: monitoring size “ne oldu?”yu söyler; observability “neden oldu?”yu bulmanızı kolaylaştırır. Bunun için üç teknik sinyal + bir kullanıcı katmanı gerekir:
- •Log: Olay kaydı (ne hata verdi, hangi parametreyle?)
- •Metric: Sayısal sinyal (error rate, latency, throughput, saturation)
- •Trace: İstek zinciri (frontend → API → servis → DB)
- •RUM: Gerçek kullanıcı deneyimi (CWV, JS errors, etkileşim, drop noktaları)
Observability nedir, logging’den farkı nedir?
Logging, olayları kaydetmektir; observability ise log+metric+trace ve RUM’u birleştirip bir olayın kök nedenini ve kullanıcı etkisini ortaya çıkarmaktır. Tek başına log, “hata var” der; observability “bu hata şu release’ten sonra başladı, şu kullanıcı segmentini etkiliyor, şu endpoint’te yoğunlaşıyor” diyebilir.
Özellikle trafik, entegrasyon ve işlem hacmi büyüdüğünde web ve yazılım hizmetlerinde web observability yaklaşımı, performans, hata ve kullanıcı deneyimi sinyallerini aynı mimaride toplamanın neden önemli olduğunu netleştirir.
Mini Check
- •Log, metric ve RUM ayrı ayrı var ama birbirine bağlanmıyor mu?
- •Bir hatayı “kullanıcı etkisi” ile görebiliyor musunuz?
- •Debugging süresi (MTTR) uzuyor mu?
Ne yapmalıyım?
- • Önce “Altın sinyaller”i belirle: latency, traffic, errors, saturation
- • Her kritiğe RUM ekle: CWV + JS error + drop noktası
- • Log’lara correlation ID ekleyip tüm katmanlarda taşı

2. Frontend ve Backend Tarafında Neleri İzlemeliyiz?
Kurumsal web’de “sorun” iki yerde görünür: kullanıcı ekranında ve backend’de. Bu yüzden izleme listesi iki taraflı olmalı.
Frontend izleme (RUM + client signals)
- •CWV: LCP/INP/CLS trendi (sayfa tipi bazında)
- •JS errors: hata türü + tarayıcı/cihaz + release versiyonu
- •Network errors: timeout, 5xx, DNS, CORS (Varsayım)
- •User actions: kritik CTA tıklamaları, form submit, rezervasyon adımı
- •Session context: sayfa tipi, ülke/dil, cihaz (Varsayım)
Backend izleme (API/servis sinyalleri)
- •Error rate: 4xx/5xx ayrımı
- •Latency: p50/p95/p99
- •Throughput: istek sayısı
- •Saturation: CPU/mem, DB bağlantı havuzu (Varsayım)
- •Dependency health: üçüncü parti (ödeme, CRM, OTA) hataları
Mini Check
- •“Frontend hata var ama backend temiz” senaryosunu görebiliyor musunuz?
- •p95 latency yükselince alarm var mı?
- •Üçüncü parti bağımlılıklar ayrı izleniyor mu?
Ne yapmalıyım?
- • Frontend: JS error + CWV + kritik action event’lerini “tek panel”de topla
- • Backend: golden signals dashboard kur (p95, error rate, throughput)
- • Dependency’leri ayrı alarm’la (ödeme/CRM/OTA)
3. Kullanıcı Deneyimi (RUM) ve Teknik Sağlık
Bir site “ayakta” olabilir ama kullanıcı için “işe yaramaz” olabilir. Bu yüzden RUM, teknik sağlığın üstüne “işe yararlılık” katmanı ekler. RUM’u doğru kurgulamazsanız, sadece sentetik testlere bakıp gerçek kullanıcıyı kaçırabilirsiniz.
RUM metrikleri (CWV + davranış sinyalleri)
- •CWV: sayfa tipi + cihaz + ağ kalitesi kırılımı
- •JS errors: error fingerprint + release etiketi
- •Interaction: tıklama gecikmesi, form completion
- •Drop noktaları: funnel step drop (otel: ödeme; B2B: form submit)
Teknik sağlık metrikleri (ops-friendly)
- •Incident sayısı / MTTR
- •Release sonrası hata artışı
- •Alert doğruluğu: kaç “false positive”?
- •Log kalite: PII sızıntısı var mı?
Key Statistics / Data Point (sheet): İyi kurgulanmış observability yapısına sahip projelerde, ciddi hatalar çoğu zaman kullanıcı şikâyetine gerek kalmadan log/metric/alert kombinasyonuyla fark edilebiliyor. (Bu veri noktası abartısız şekilde kullanıldı.)
Bu noktada kurumsal site logging ve RUM yaklaşımı, teknik hata sinyallerini event ve funnel verileriyle birlikte değerlendirerek gerçek kullanıcı etkisini daha doğru okumayı sağlar.
Mini Check
- •RUM verisi “iş etkisi” ile bağlanıyor mu (rezervasyon/lead)?
- •Release sonrası ilk 60 dakika “gözlem penceresi” var mı?
- •Alert fatigue (çok alarm, az değer) yaşanıyor mu?
Ne yapmalıyım?
- • RUM’u “sayfa” değil “görev” bazında izle (rezervasyon/lead)
- • Release sonrası 60 dakika “war room lite” rutini koy
- • Alarm’ları azalt: kritik 5 metrik + kritik 5 senaryo

4. Otel ve B2B İçin İzlenebilirlik Senaryoları
Observability’nin değeri, “genel dashboard” değil, senaryo bazlı alarmdır. Otel ve B2B’de en kritik senaryolar farklıdır.
Otel senaryoları (rezervasyon hataları + drop noktaları)
- •Rezervasyon adım bazında drop (tarih → oda → fiyat → ödeme)
- •Ödeme sağlayıcı hataları (Varsayım: 3DS/timeout)
- •Call/WhatsApp tıklaması artıyor ama rezervasyon düşüyorsa: UX friksiyonu
- •Kampanya landing’lerinde CWV bozulması (LCP yükselişi)
B2B senaryoları (dashboard/performance alert’leri)
- •Dashboard p95 latency artışı
- •Rapor export hataları (Varsayım)
- •Login hataları / session expiry artışı
- •Lead form submit düşüşü + JS error artışı (frontend kaynaklı)
Kurumsal web sitesinde hangi log ve metrikleri izlemeliyim?
Minimum set: error rate (4xx/5xx), latency (p95), request throughput, dependency error’ları ve RUM (CWV + JS error + kritik funnel event’leri). Otelde rezervasyon/ödeme adımları; B2B’de dashboard/login/lead event’leri “iş KPI” olarak izlenmelidir.
Mini Check
- •Otelde rezervasyon adımları event bazında ölçülüyor mu?
- •B2B’de dashboard p95 ve error rate alarm’ı var mı?
- •Üçüncü parti bağımlılıklar ayrı panelde mi?
Ne yapmalıyım?
- • Otel: “Rezervasyon Sağlık Paneli” kur (drop + ödeme hatası + CWV)
- • B2B: “Portal Sağlık Paneli” kur (login + p95 + JS error)
- • Her iki paneli iş KPI’larıyla bağla (/tr/raporlama/satis-donusum)
5. Log Seviyeleri, Korelasyon ve PII Güvenliği
Logging, “ne kadar çok log o kadar iyi” değildir. Kaliteli log; doğru seviyede, doğru bağlamla ve PII sızdırmadan tutulur. Ayrıca log’un tek başına anlamlı olması için korelasyon gerekir: aynı isteğin frontend event’i, backend request’i ve third-party çağrısı aynı “trace/correlation ID” ile bağlanmalıdır.
Log seviyeleri (error/warn/info) ve pratik kural
- •error: kullanıcıyı etkileyen arızalar (alarm tetikleyebilir)
- •warn: riskli ama servis devam ediyor (trend izlenir)
- •info: operasyonel iz (sınırlı, maliyet kontrollü)
PII/KVKK ve log güvenliği
- •Form verilerini log’a yazma (Varsayım: maskeleme)
- •Token/şifre gibi secrets asla log’lanmaz
- •Log erişimi RBAC ile sınırlandırılır
- •Saklama süresi (retention) politika ile belirlenir
Privacy ve erişim kontrolü tarafında güvenlik olayları için log takibi, şüpheli davranışların, veri erişimlerinin ve log güvenliği politikalarının geliştirme sürecine baştan dahil edilmesini destekler.
Mini Check
- •Log’larda PII var mı (telefon/e-posta)?
- •Correlation ID her katmanda var mı?
- •Log retention ve erişim politikası yazılı mı?
Ne yapmalıyım?
- • Log şemasını standardize et (fields: release, env, user_segment, correlation_id)
- • PII maskeleme kuralı koy
- • “Log maliyet budget” belirle (gereksiz info log’u kes)
6. Dashboard ve Alert Tasarımı
Observability’nin son adımı “dashboard çöplüğü” olmamalı. En iyi yaklaşım: 3 katman dashboard + 2 katman alarm.
Raporlama katmanında teknik izleme dashboard’u, ürün, pazarlama ve teknik ekiplerin aynı sinyallere farklı kırılımlarla bakabilmesi için observability çıktısını daha görünür hale getirir.
- Executive/Business: Rezervasyon/lead sağlık + drop + revenue proxy (Varsayım)
- Ops/Technical: golden signals + dependency health
- Debug: trace ve hata drill-down
| Alarm | Eşik | Kim Aksiyon Alır? | İlk 10 Dakika Aksiyonu |
|---|---|---|---|
| Rezervasyon/Lead drop | %X düşüş (Varsayım: baseline’a göre) | Ürün+Ops | Release var mı? Event çalışıyor mu? |
| 5xx error rate | %1+ (Varsayım) | DevOps/Backend | Rollback/mitigation, dependency check |
| p95 latency | %Y artış (Varsayım) | Backend/Platform | Cache/DB/dependency kontrol |
| JS error spike | release sonrası artış | Frontend | Rollback/feature flag (Varsayım) |
| CWV (LCP) bozulma | kritik sayfalarda trend | FE+Perf | Görsel/JS değişimi var mı? |
Benzer şekilde observability verisini yorumlamak, log ve RUM sinyallerinin yalnız teknik hata listesi olarak değil, dönüşüm ve kullanıcı deneyimi etkisiyle birlikte değerlendirilmesine yardımcı olur.
Mini Check
- •Alarmlar aksiyon üretiyor mu, yoksa bildirim gürültüsü mü?
- •“Kim aksiyon alır?” satırı net mi?
- •Alarm sonrası runbook var mı?
Ne yapmalıyım?
- • Alarm sayısını sınırlı tut: kritik 10 alarm ile başla
- • Her alarm için runbook yaz: triage → mitigation → verify
- • İş KPI panelini teknik panelle aynı sayfada ilişkilendir (/tr/raporlama/satis-donusum)
7. Go-Live ve Sürekli İyileştirme Rutini
Observability kurulduktan sonra “bitti” değildir. Araçlar, CWV tanımları ve stack değiştikçe eşikler ve dashboard’lar güncellenmelidir.
Refresh notu (sheet): APM/RUM araçları, log altyapıları ve CWV tanımları geliştikçe diyagramlar ve eşikler güncellenmelidir.
Release sonrası kontrol (60 dakika kuralı)
- •İlk 15 dk: error rate + login/rezervasyon smoke
- •15–30 dk: p95 latency + dependency health
- •30–60 dk: RUM (CWV, JS errors) trend
Özellikle release sonrası hata takibi, yeni versiyonların staging-prod geçişinden sonra rollback veya hotfix kararını daha veriye dayalı hale getirir.
Haftalık “observability review” (30 dk)
- •En çok hata üreten 5 endpoint
- •En çok drop olan 2 adım
- •En çok alarm üreten 3 kural (gerekirse kaldır)
Ayrıca SEO performansına teknik sorun etkisi, yavaşlık, hata artışı veya render problemlerinin organik görünürlük tarafında nasıl yankılandığını düzenli izlemenizi sağlar.
Mini Check
- •Go-live sonrası “izleme penceresi” rutin mi?
- •Haftalık review var mı?
- •Dashboard’lar yaşayan doküman mı?
Ne yapmalıyım?
- • Roadmap’e observability bakım sprint’i ekle (ayda 1)
- • Alarm eşiklerini “baseline” ile güncelle
- • Observability çıktısını iş raporlamasına bağla (/tr/veri-analiz-ve-raporlama)



8. Web Sitesi İzlenebilirlik (Log/Metric/RUM) Planlama Şablonunu İndir — Yazılım / Observability
Web Sitesi İzlenebilirlik (Log/Metric/RUM) Planlama Şablonunu İndir — Yazılım / Observability (v1.0)
Bu şablon, kurumsal web sitelerinde log, metric, trace ve RUM katmanlarını iş KPI’larıyla birlikte planlamanızı sağlar. Otel ve B2B senaryolarında rezervasyon/lead drop, JS hata artışı, p95 latency ve CWV bozulması gibi kritik sinyaller için dashboard ve alert eşikleri oluşturur. Amaç; “bozuldu mu?” sorusundan “neden bozuldu, kaç kişiyi etkiledi, kim aksiyon alacak?” seviyesine geçmektir.
Kim Kullanır?
Ajans teknik lideri, DevOps/backend, frontend/performance ekibi, ürün/proje sahibi, otel revenue/e-commerce ve B2B ürün ekipleri.
Nasıl Kullanılır?
- Kritik kullanıcı görevlerini ve iş KPI’larını seçin: rezervasyon, lead, login, dashboard, ödeme.
- Log/metric/trace/RUM sinyallerini bu görevlerle eşleştirip dashboard katmanlarını oluşturun.
- Alert eşiklerini baseline’a göre kalibre edip runbook ve ilk 10 dakika aksiyonlarını yazın.
Ölçüm & Önceliklendirme (Kısa sürüm)
PDF içinde: Problem→Kök Neden→Çözüm tablosu + 14 gün sprint planı + önce/sonra KPI tablosu
9. Sonuç: İzlenebilirlik, teknik sağlık ile iş etkisini aynı ekranda gösterir
Kurumsal web sitelerinde iyi observability, yalnızca hata kaydı tutmak değildir. Log, metric, trace ve RUM birlikte kurgulandığında; bir problemin ne zaman başladığı, hangi release ile ilişkili olduğu, kaç kullanıcıyı etkilediği ve hangi iş KPI’ına zarar verdiği daha hızlı anlaşılır.
Otel ve B2B projelerinde en değerli izleme modeli; rezervasyon/lead sağlığı, CWV, JS hataları, p95 latency, dependency health ve alert runbook’larını tek operasyon düzeninde birleştirir. Bu yaklaşım, ekiplerin “şikâyet gelince bakarız” yerine proaktif teşhis, hızlı aksiyon ve sürekli iyileştirme kültürü kurmasını sağlar.
İzleme, hata takibi ve dashboard katmanını doğru kurgulamak isteyen ekipler için izlenebilir web sitesi geliştirme desteği süreci; mimari, deployment ve raporlama tarafını birlikte ele alır. Uygulama detaylarını ayrıca Web sitesi geliştirme hakkında sık sorulan sorular sayfasında da inceleyebilirsiniz.
Bir Sonraki Adım
Log/metric/trace+RUM mimarinizi kurup otel/B2B senaryolarına uygun dashboard ve alarm setini birlikte tasarlayalım.
Sık Sorulan Sorular
Observability nedir, logging’den farkı nedir?▾
Kurumsal web sitesinde hangi log ve metrikleri izlemeliyim?▾
RUM neden önemlidir?▾
Alert eşikleri nasıl belirlenmeli?▾
Log’larda PII/KVKK riski nasıl yönetilir?▾
Otel sitelerinde observability en çok nerede değer üretir?▾
B2B portallerde hangi izleme senaryoları kritiktir?▾
Go-live sonrası izleme rutini nasıl olmalı?▾
İlgili İçerikler